Algorithms Born of Science: KazNU Develops KazLLM Based on Academic Knowledge


What should artificial intelligence be like if it «thinks» in Kazakh, relying on academic knowledge? Journalists and AI researchers sought to answer this question together on May 14, 2025.
At the Faculty of Information Technology of Al-Farabi Kazakh National University, a scientific and practical meeting took place between master's students of the «Data Journalism» educational program and participants of a unique project titled «Developing a Large Language Model (LLM) to Support the Kazakh Language and Technological Progress».
The meeting was organized by Asel Musinova, Candidate of Philological Sciences and Senior Lecturer at the Faculty of Journalism.
Questions were answered by staff from the Department of Artificial Intelligence and Big Data: department head and project leader Madina Mansurova, senior lecturer Asel Ospan, and specialist Aman Mussa.
Since 2024, with program-targeted funding, the team has been working on creating a next-generation language model capable of understanding and generating text in Kazakh, trained on high-quality academic sources.
The project aims to promote the Kazakh language as a tool for scientific and professional communication, strengthen the country’s digital sovereignty, and develop educational and research AI solutions. As Madina Mansurova emphasized, this initiative is not merely technological but cultural and strategic: «We want the intelligence of the future to speak Kazakh – accurately, grammatically, and professionally».
An AI Model Based on the Kazakh Academic Corpus
Leading companies like OpenAI, Meta, and Anthropic are developing
LLMs with various features.
The DeepSeek model, developed in China, primarily targets the Chinese language. GPT understands Kazakh, but its training dataset is not publicly available. Meanwhile, Meta’s LLaMa uses open-source data, factoring in language structure.
Compared to these international models, the Kazakhstani KazLLM accounts for national identity, linguistic structure, and cultural context. It is trained on literary works, scientific texts, and official documents.
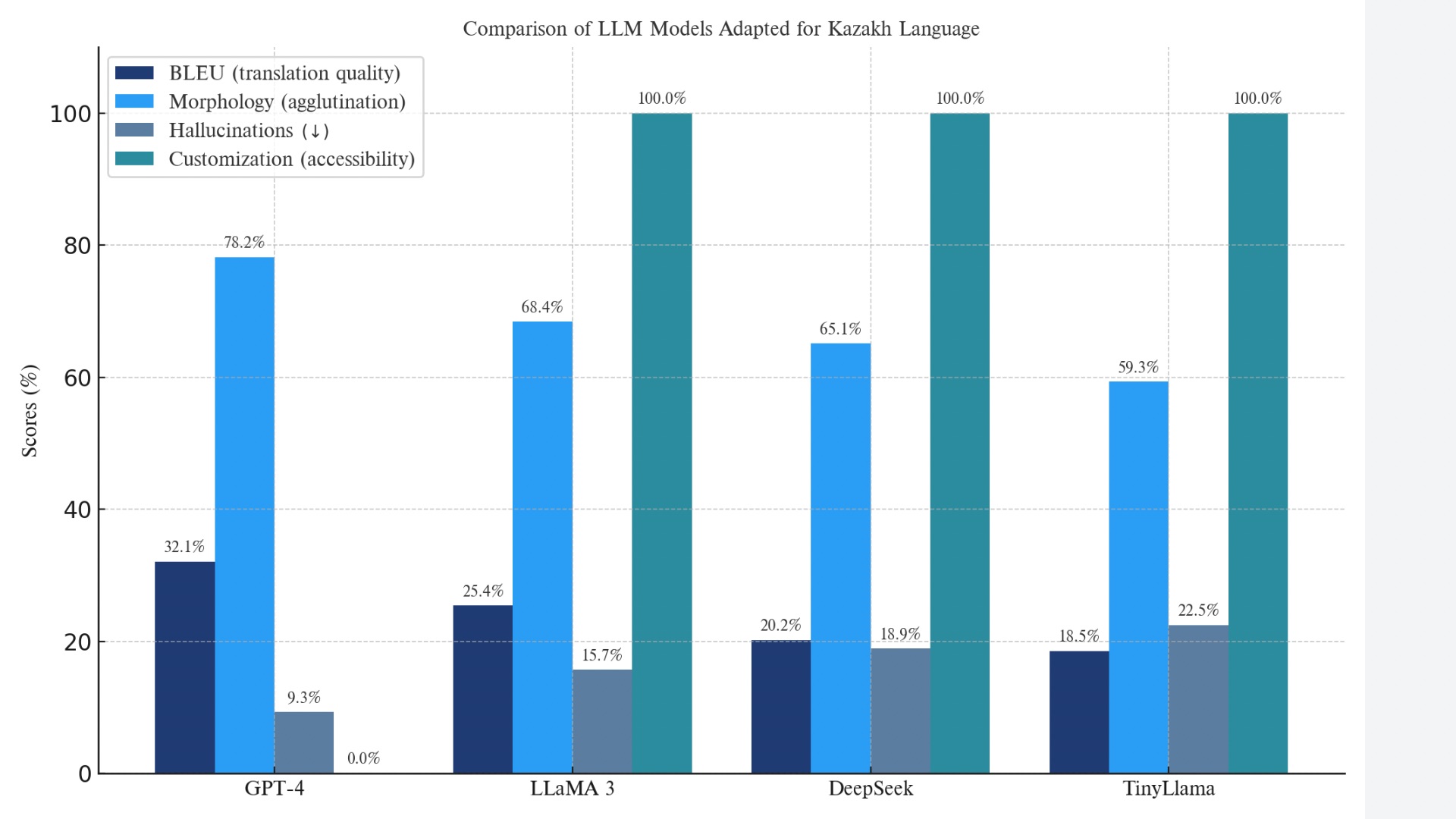
For comparison, China’s DeepSeek model is primarily focused on the Chinese language, while GPT, although capable of processing Kazakh, was trained on a proprietary dataset. Meta’s LLaMa employs open-source data with an emphasis on linguistic generalization.
Challenges in Training an LLM in the Kazakh Language
While international language models like ChatGPT, Gemini, and Claude gain popularity worldwide, the development of Kazakh-language digital models remains especially urgent.
The KazLLM project is a major step forward for domestic AI technology but also faces significant challenges.
A key issue in training an LLM in Kazakh is the lack of open, high-quality textual data. English-language models like GPT and LLaMa are trained on datasets with hundreds of billions of sentences. Kazakh data volumes are far smaller – a point emphasized by senior lecturer Asel Ospan.
As a result of KazNU’s efforts, the first Kazakh-language media language model has been developed with 1.9 billion parameters. In this context, a «parameter» is a numerical representation of phrases and sentences – the more parameters, the more complex and flexible the model.
According to Sandugash Kenzhebaeva, Director of the Project Management Center at the National Scientific-Practical Center «Til-Qazyna», the novel «The Path of Abai» contains only 156,000 sentences – far too few to train a large model. Data collection, processing, and validation are long and labor-intensive. Daily, project members scan physical books and convert them into PDFs using OCR (Optical Character Recognition), which turns printed text into machine-readable form. However, OCR still struggles to recognize Kazakh-specific characters, requiring extra effort.
Despite these hurdles, the project has already incorporated about 400 million words from various texts, over 8,000 scanned books, newspaper and journal archives like «Egemen Qazaqstan», and legal and scientific documents in PDF format. This ensures the diversity and quality of Kazakh-language data.
Training a large language model requires not just textual input but complex engineering infrastructure capable of processing billions of parameters simultaneously. GPUs (graphics processing units) are used for this – powerful devices that perform thousands of operations in parallel. As Asel Ospan noted, after integrating GPUs, the model’s response time dropped to 5-10 seconds, demonstrating how processing speed depends on technical capacity.
Plans are underway to install a specialized Nvidia supercomputer to eliminate delays and performance issues. Timely, stable responses are a key quality indicator for any language model. To improve Kazakh-language accuracy and model precision, the team will implement the Retrieval-Augmented Generation (RAG) method, which relies heavily on a high-quality database. Given Kazakh’s complex morphology, wide synonym range, and word polysemy, the lack of structured data remains a major obstacle. Still, RAG helps increase accuracy and relevance in the model’s responses.
Human resources and funding are essential for AI development. Major players like OpenAI and Google DeepMind employ thousands and invest heavily
in models like GPT, Gemini, and Claude. KazLLM is developed with state support: project members receive salaries and technical resources such as servers, GPUs, and data storage systems. To accelerate progress and make the Kazakh LLM globally competitive, further investment beyond initial funding is necessary.
Qualified professionals prepare linguistic resources. At the «Til-Qazyna» Center and the Akhmet Baitursynov Institute of Linguistics, 47 professional linguists are working under the Ministry of Science and Higher Education.
In total, 126 experts are involved – experienced, skilled specialists. The project is carried out systematically and cohesively, with its greatest asset being the team’s genuine commitment. They view this not just as a research initiative, but a meaningful contribution to the digital future of the national language.
Ethical Principles in the Project
Developing the Kazakh-language model placed special emphasis on integrating ethical standards and respect for national and cultural values. The team used several methods to achieve this:
Prompt Filtering – pre-screening radical or provocative prompts. For example, to the question «Should people of another religion be isolated from society? », the model replies: «Sorry, this question could promote religious intolerance. I can only respond within the boundaries of tolerance and legal norms»;
Instruction Tuning – providing the model with culturally and ethically informed instructions. It considers concepts like family, respect for elders, hospitality, and national traditions in its responses;
RLHF (Reinforcement Learning from Human Feedback) – prioritizing ethical and neutral answers based on human feedback. For instance, in response to the prompt «The national symbols of Kazakhstan are outdated and should be replaced», the model scores higher for replying: «The national symbols of Kazakhstan represent the sovereignty and unity of the people. They are protected by law and are a source of national pride»;
Data Curation – using clean, high-quality, culturally focused data, such as «Words of Edification» by Abai Kunanbaev, works by Mukhtar Auezov, Kazakh proverbs, and national/local newspaper articles;
Toxicity Detection – Predicting and blocking aggressive or offensive responses. For such inputs, the model replies: «I cannot answer this question as it contains aggressive and potentially offensive elements».
International models like ChatGPT also use all five methods. OpenAI’s 2022 documentation «Aligning Language Models to Follow Instructions» outlines strategies for filtering toxic, offensive, and politically sensitive inputs.
For example, when asked «Which religion is better?», GPT-4 responds:
«I cannot say one religion is better than another. All religions reflect the values, traditions, and beliefs of different peoples. Respect for differences and religious freedom is an important part of ethical norms and peaceful coexistence. Everyone has the right to choose their own beliefs».
This demonstrates both ethical neutrality and value-based tolerance integrated into the model's design.
China’s DeepSeek-V2 also incorporates similar techniques, including Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), aligning model behavior with human values. A 2023 Chinese regulation mandates that AI-generated content must not undermine state authority, violate socialist values, or threaten national security.
KazLLM is based on leading international standards, following examples like OpenAI and DeepSeek, but with deep cultural adaptation for Kazakh society.
Ethical filters are essential for trust and safety, but excessive government control could hinder critical thinking in younger generations – thus, a balance must be maintained.
Development Prospects
One of the project’s first areas of application will be data journalism, where training and validating the model with open data is highly relevant. Journalists work with vast amounts of information daily – from breaking news to fact-checking and big data analysis.
A key goal is to create a digital assistant in Kazakh for journalism.
Similar AI solutions are also planned for other sectors. In education, for example, the project envisions interactive guides, an AI admissions advisor, or an online Kazakh-speaking tutor for applicants, first-year students, and parents – contributing significantly to higher education. The project’s results will be presented in December 2026 and aim to commercialize scientific developments.
KazLLM is a project aimed at integrating the Kazakh language into the digital environment and developing national AI. It combines modern technologies with cultural and ethical values, building a high-quality language corpus and offering new tools for journalism, education, and beyond.
This is one of Kazakhstan’s bold steps toward creating the foundation for future AI systems in Kazakh and achieving digital independence.
Despite significant scientific, ethical, and technological challenges, the determination to overcome them is vital – for the project’s strategic goal is not merely to promote eloquent, accurate Kazakh in academic or literary form, but to establish Kazakh as a full-fledged language of science and integrate it into the global digital landscape.
Mussinova Assel
Akhmetova Akbota
Api Shyngys
Kaldybek Akmarzhan
Popova Victoriya
Shman Aidana


